Disclaimer: These are purely my personal views and do not represent my employer.
Today, StorageGRID 10.1 is available for customers to download and use. StorageGRID 10.1 provides
- Hierarchical erasure coding
- An appliance form factor
- Amazon S3 as a cloud storage
- Multiple performance and efficiency enhancements
- Openstack glance integration
- Tenant management APIs
Lots of great new stuff! But what is really compelling is how policy based management combined with erasure coding & cloud storage drives lower $/GB while not being a one trick pony.
We will cover hierarchical erasure coding later, this blog post will talk in detail about how policy based data management really helps manage the $/GB for data stored in the object store. I will use StorageGRID Webscale as an example and show the capabilities that are essential for an object storage solution.
Policy based data management is really critical for object storage solutions. This is because they very quickly grow and become the repository for a lot of data, across multiple use cases.
At this scale, it is really important that every use case meets its $/GB target.
Erasure coding achieves great storage savings, but incurs its severe performance penalty – Object sizes need to be relatively larger, you need more compute, and repair traffic is not something you want to talk about.
Replicated objects are great, for small objects and for lower latency workloads, but they take up more space.
Finally, being able to protect objects at the desired level based on its value is really important. Early in their life cycle, objects need to be protected very robustly, but as time wears on the value of that data changes, and this needs to reflect in the cost of the infrastructure.
Without policy based data management, none of this is possible.
Policy based data management in a storage systems systems has been hard to do for multiple reasons –
- Applications tend to make broad assumptions about performance & latency of the storage system
- Traditional storage semantics do not support data movement, leading to clunky work-arounds such as stubs
- ‘Applications’ written for traditional storage systems tend to mix ‘control-plane data’ (e.g database) with ‘data-plane data’ (eg images). This makes it very hard for any policy based data movement to be really successful without significant intelligence either from the application or from the storage admin.
All this changes with object storage, where now it is possible to move data from an expensive tier of storage to a cheaper storage, change the kind of data protection used – whether that is replicated storage to erasure coded storage or cloud storage, each with its own performance and cost profile.
To enable policy based data management you need three things
- A location to store the data
- Conditions that define when to move the data
- A data movement engine that is flexible
Where to store the data
Let’s look at how StorageGRID Webscale defines storage pools. There are three key concepts here
- Storage Node : A storage node actually manages the data. A storage node can be very small to very large (100’s of TB)
- Storage grade: Defines what kind of node is a storage node
- Site: A site is an administrative entity.
The key aspect of a site is that it is ‘connected’ to other sites and there is a non-zero cost of moving data between sites. This concept of a site is unique to StorageGRID Webscale.
The diagram below is a good summary of how all this comes together.
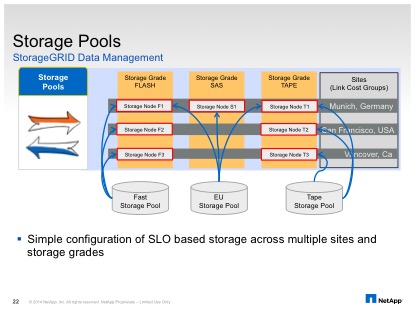
There are a few things that I want to draw attention to in this diagram
- Sites: StorageGRID understands that a ‘site’ is an administrative construct that has two different implications.
First, there is a cost of moving data from a site in Germany to a site in the US. This cost is real, and needs to be modeled into the object storage system. A number of object storage solutions use labels and naming conventions to draw the distinction between different sites. This is good and sufficient if the only problem is to group different storage nodes together. But an intelligent object store needs to do more.
Data movement and data placement needs to take into account real world WAN costs.
Second, a site is a data protection / failure domain and this has to be recognized in how erasure coding is done.
- Storage grades: Being able to assign different storage grades lets a real world definition of performance (or any other metric) be translated into the object store.
This enables SLOs to be configured and used with different application end points.
- Storage pools are combinations of storage nodes and one storage node can be in more than one storage pool
This is the fundamental unit of data management.
The combination of sites, storage grades and storage pools enables StorageGRID Webscale to do many interesting things – being able to retain data within a region, be able to preferentially place data in a particular storage pool for performance regions, optimize WAN traffic, and be able to treat storage resources across multiple sites as one large pool.
StorageGRID Webscale has been designed bottoms-up to be a true multi-site object storage system.
Under what conditions to move the data
StorageGRID defines policies on a ‘per object’ basis. Every object is evaluated and the applicable policy applied.
StorageGRID Webscale uses metadata to trigger data movement. The metadata available includes all the typical metadata fields– Object size, date etc. But what makes StorageGRID unique is its ability to use custom application metadata. In the diagram below we are using a combination of different metadata fields to select the set of objects that a policy is going to be applied on
Lets look at an actual screen shot from the StorageGRID Webscale UI.
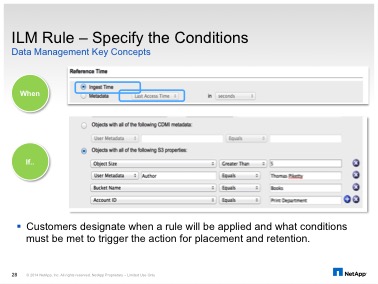
There are a many really interesting things to note here
ALL the application metadata is available for use via policy. Metadata in StorageGRID is ‘active’. It is not just stored as data on the system.
The user metadata field is ‘free text’ – This implies no pre-configuration of the metadata. If your application adds a new metadata field, the admin has to just enter the new field into the UI. Consider what happens when your application version gets revised and new metadata fields are added. All of this is seamlessly supported.
StorageGRID Webscale can promote data based on access. This is important so that application service levels can be met. As cold data becomes hot again, data can be promoted to a faster tier of storage, or maybe a site closer to where the application is so that higher performance can be delivered.
This is critical for object stores since this feature provides the ability for data to toggle between a full copy or an erasure coded copy. Being able to move data between these two data protection schemes helps balance cost savings from using lesser storage with erasure coding, versus the performance implications.
How is the data moved?
Lets look at exactly how data is moved in StorageGRID Webscale. The screenshot below provides a good overview
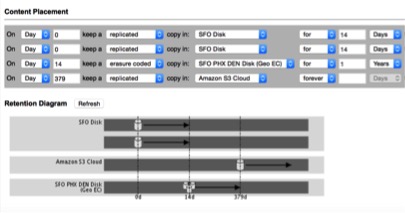
The intuitive display makes it really clear how the policy translates to real world data copies.
In addition to erasure-coded storage and replicated storage, StorageGRID is able to move data to the AWS S3 cloud, all under policy control.
While the data moves among these multiple tiers of storage, applications continue to access data via StorageGRID Webscale. All of this storage management is transparent to end user applications.
Clearly, object storage solutions need to do a lot more than they do today. Object storage lets the underlying storage do interesting things with data management.
Policy based data management is key. It lets us manage the cost & performance requirements by use case in a dynamic manner, responding to real time application requirements. The object store is now not a one trick pony, limited to specific object sizes, or specific use cases. Policy based management lets the object store be the single tier-2 store solution across your infrastructure, eliminating storage silos, and providing a simple provisioning and management interface.
Hopefully, StorageGRID Webscale is starting to bridge that gap.
